欢迎您访问广东某某机械环保科有限公司网站,公司主营某某机械、某某设备、某某模具等产品!
全国咨询热线: 400-123-4567



 哈希游戏
哈希游戏 哈希游戏| 哈希游戏平台| 哈希游戏APP
哈希游戏| 哈希游戏平台| 哈希游戏APP哈希游戏- 哈希游戏平台- 哈希游戏官方网站,(后者通常使用分块数组来实现,比如:一个数组的数组)。结果大部分会和你预期的保持一致,但是会存在一些违反直觉的东西。作为实例:在序列链表的中间位置做插入或者移除操作被认为会比数组快,但如果该元素是一个 POD 类型,并且不大于 64 字节或者在 64 字节左右(在一个 cache 流水线内),通过对要操作的元素周围的数组元素进行移位操作要比从头遍历链表来的快。这是由于在遍历链表以及通过指针插入/删除元素的时候可能会导致不少的 cache 缺失,相对而言,数组移位则很少会发生。(对于更大的元素,非 POD 类型,或者你已经有了指向链表元素的指针,此时和预期的一样,链表胜出)
多亏了类似 Baptiste 这样的数据,我们知道了内存布局如何影响序列容器。但是关联容器,比如 hash 表会怎么样呢?已经有了些权威推荐:[2](此时,我们没必要追踪指针),以及[3](这种情况下,我们可以在每一个 cache 流水线中得到更多的 key), 这可以在我们必须查找多个 key 时提高局部性能。这些想法很有意义,但再一次的说明:测试永远是好习惯,但由于我找不到任何数据,所以只好自己收集了。
UM: std::unordered_map 。在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,UM 是以链表的形式实现,所有的元素都在链表中,bucket 数组中存储了链表的迭代器。VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
UM: std::unordered_map 。在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,UM 是以链表的形式实现,所有的元素都在链表中,bucket 数组中存储了链表的迭代器。VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
OL,DO1 和 DO2 的实现将共同的被称为 OA(open addressing)——稍后我们将发现它们在性能特性上非常相似。在每一个实现中,单元数从 100 K 到 1 M,有效负载(比如:总的 key + value 大小)从 8 到 4 k 字节我为几个不同的操作记了时间。 keys 和 values 永远是 POD 类型,keys 永远是 8 个字节(除了 8 字节的有效负载,此时 key 和 value 都是 4 字节)因为我的目的是为了测试内存影响而不是哈希函数性能,所以我将 key 放在连续的尺寸空间中。每一个测试都会重复 5 遍,然后记录最小的耗时。
你可以[5]。这些代码只能在 64 机器上编译(包括Windows和Linux)。在 main() 函数顶部附近有一些开关,你可把它们打开或者关掉——如果全开,可能会需要一两个小时才能结束运行。我收集的结果也放在了那个打包文件里的 Excel 表中。(注意: Windows 和 Linux 在不同的 CPU 上跑的,所以时间不具备可比较性)代码也跑了一些单元测试,用来验证所有的 hash 表实现都能运行正确。
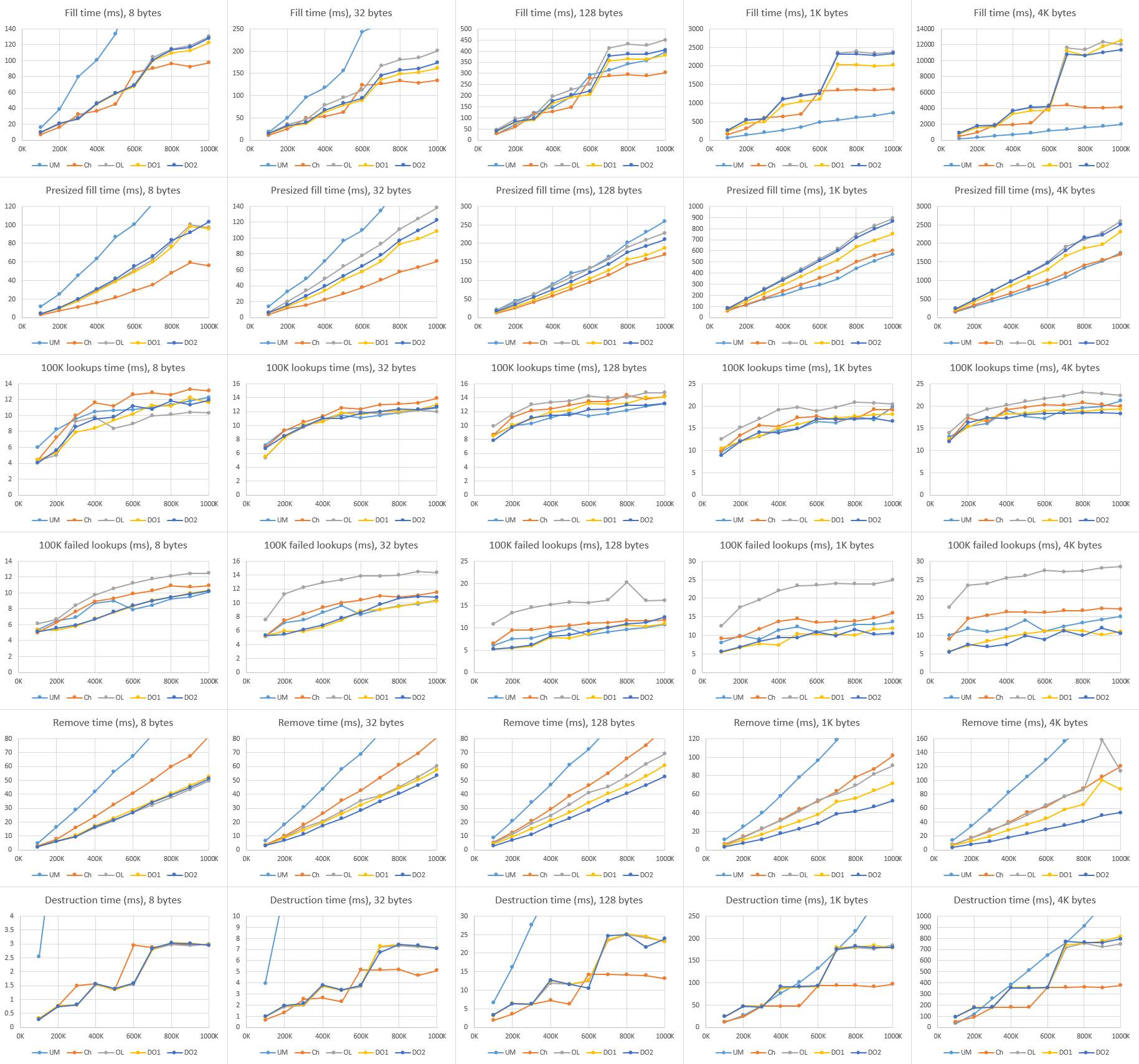
在小负载的情况,UM 几乎是所有 hash 表中表现最差的 —— 因为 UM 为每一次的插入申请(内存)付出了沉重的代价。但是在 128 字节的时候,这些 hash 表基本相当,大负载的时候 UM 还赢了点。因为,我所有的实现都需要重新调整元素池的大小,并需要移动大量的元素到新池里面,这一点我几乎无能为力;而 UM 一旦为元素申请了内存后便不需要移动了。注意大负载中图表上夸张的跳步!这更确认了重新调整大小带来的问题。相反,UM 只是线性上升 —— 只需要重新调整 bucket 数组大小。由于没有太多隆起的地方,所以相对有效率。
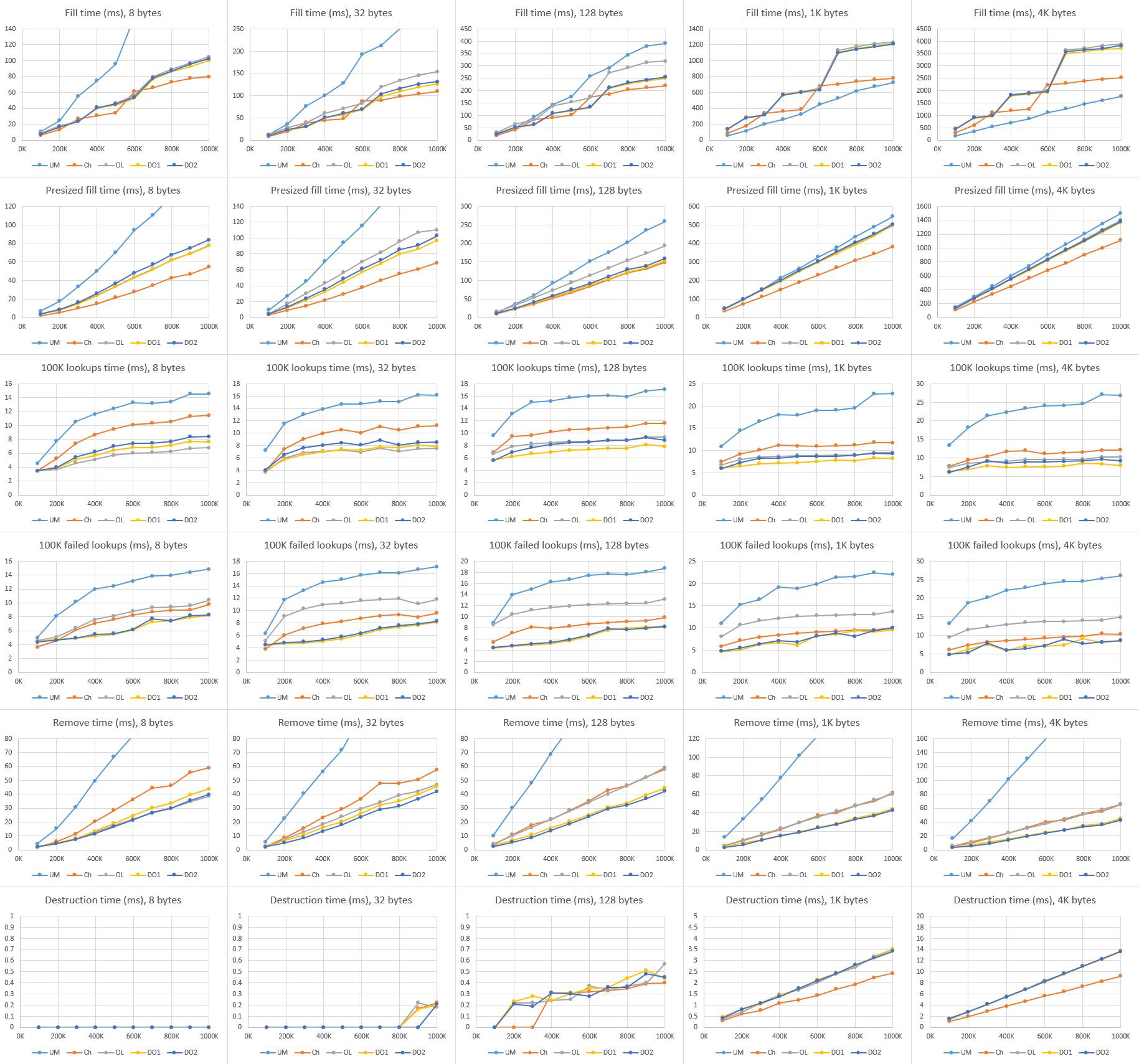
在我的实现中,小负载的时候,析构的消耗太少了,以至于无法测量;在大负载中,线性增加的比例和创建的虚拟内存页数量相关,而不是申请到的数量?同样,要比 Windows 中的析构快上几个数量级。但是并不是所有的都和 hash 表有关;我们在这里可以看出不同系统和运行时内存系统的表现。貌似,Linux 释放大内存块是要比 Windows 快上不少(或者 Linux 很好的隐藏了开支,或许将释放工作推迟到了进程退出,又或者将工作推给了其它线程或者进程)。
首先,在大多数情况下我们“很容易”做的比 std::unordered_map 还要好。我为这些测试所写的所有实现(它们并不复杂;我只花了一两个小时就写完了)要么是符合 unordered_map 要么是在其基础上做的提高,除了大负载(超过128字节)中的插入性能, unordered_map 为每一个节点独立申请存储占了优势。(尽管我没有测试,我同样期望 unordered_map 能在非 POD 类型的负载上取得胜利。)具有指导意义的是,如果你非常关心性能,不要假设你的标准库中的数据结构是高度优化的。它们可能只是在 C++ 标准的一致性上做了优化,但不是性能。:P
注意,我的为这些哈希表做的测试代码远未能用于生产环境——它们只支持 POD 类型,没有拷贝构造函数以及类似的东西,也未检测重复的 key,等等。我将可能尽快的构建一些实际的 hash 表,用于我的实用库中。为了覆盖基础部分,我想我将有两个变种:一个基于 DO1,用于小的,移动时不需要太大开支的负载;另一个用于链接并且避免重新申请和移动元素(就像 unordered_map ),用于大负载或者移动起来需要大开支的负载情况。这应该会给我带来最好的两个世界。
