欢迎您访问广东某某机械环保科有限公司网站,公司主营某某机械、某某设备、某某模具等产品!
全国咨询热线: 400-123-4567



 哈希游戏
哈希游戏 哈希游戏| 哈希游戏平台| 哈希游戏APP
哈希游戏| 哈希游戏平台| 哈希游戏APP哈希游戏- 哈希游戏平台- 哈希游戏官方网站hash算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法。散列就是把任意长度的输入通过散列算法变换成固定长度的输出,输入称为Key(键),输出为Hash值,即散列值hash(key),散列算法即hash()函数(
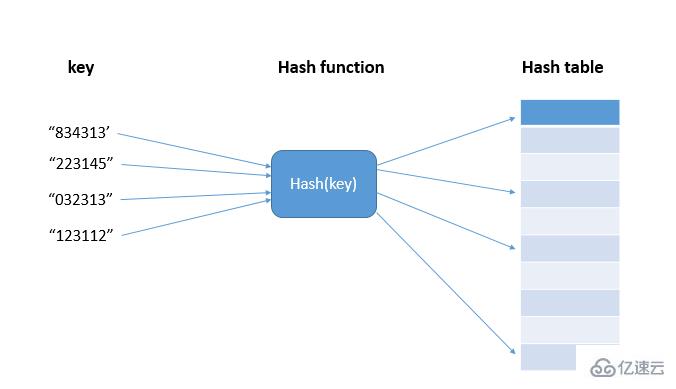
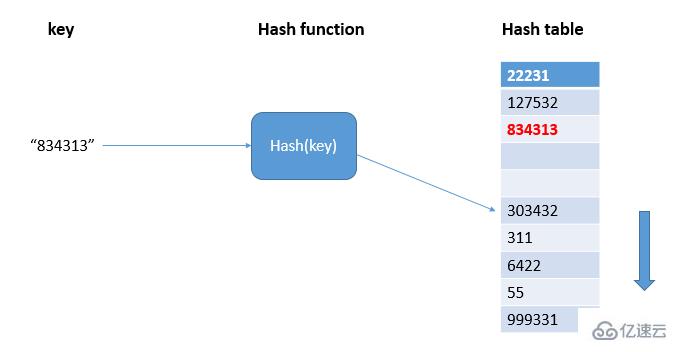
如图,834313在hash表中散列到303432的位置上,出现了冲突,则顺序遍历hash表直到找到空闲位置写入834313;当散列表中空闲位置不多的时候,散列冲突的概率就会大大增加,一般情况下,我们会尽可能保证散列表中有一定比例的空闲槽位,此时,我们用装载因子来表示空闲位置的多少,计算公式是:散列表的装载因子=填入表中的元素个数/散列表的长度。装载因子越大,说明空闲位置越少,冲突越多,散列表的性能就会下降。
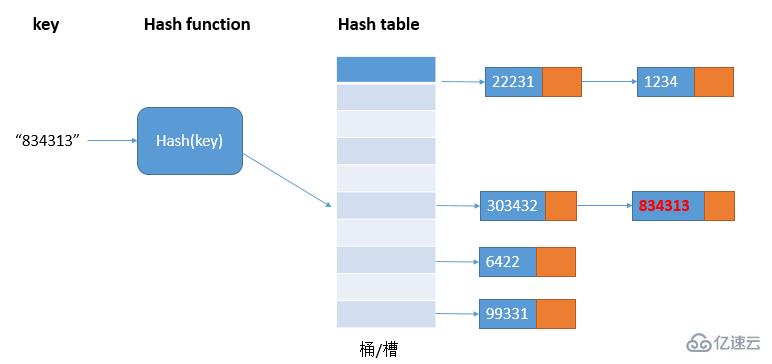
这种解决散列冲突的处理方法比较适合大对象、大数据量的散列表,而且,支持更多的优化策略,比如使用红黑树代替链表;jdk1.8为了对HashMap做进一步优化,引入了红黑树,当链表长度太长(默认超过8)时,链表就会转换成红黑树,这时可以利用红黑树快速增删查改的特点,提高HashMap的性能,当红黑树节点个数小于8个时,又将红黑树转化成为链表,因为在数据量比较小的情况下,红黑树要维护平衡,比起链表,性能上的优势并不明显。
但是,如果数据增多,原来的10台机器已无法承受,需要扩容了,这时是如果所有数据都重新计算哈希值,然后重新搬移到正确的机器上,那就相当于所有的缓存数据一下子都失效了,会穿透缓存回源到数据库,这样就可能发生雪崩效应,压垮数据库。为了新增缓存机器不搬移所有的数据,一致性哈希算法就是比较好的选择了,主要的思想是:假设我们有kge机器,数据的哈希值范围是[0,Max],我们将整个范围划分成m个小区间(m远大于k),每个机器负责m/k个小区间,当有新机器加入时,我们就将某几个小区间的数据,从原来的机器中搬移到新的机器中,这样,即不用全部重新哈希、搬移数据,也保持了各个机器上数据量的平衡。
